
AI Era: Data Engineering Challenges
Data Engineering
A recent MIT Tech Review Report shows that 88% of surveyed organizations are either investing in, adopting or experimenting with generative AI (GenAI) and 71% intend to build their own GenAI models. This increased interest in AI is fueling major investments as AI becomes a differentiating competitive advantage in every industry. As more organizations work to leverage their proprietary data for this purpose, many encounter the same hard truth: The best GenAI models in the world will not succeed without good data. This reality emphasizes the importance of building reliable data pipelines that can ingest or stream vast amounts of data efficiently and ensure high data quality. In other words, good data engineering is an essential component of success in every data and AI initiative and especially for GenAI.
What is data engineering?
As it is said, “Data is the new oil”, in order to get meaningful insights or value from any data it needs to be prepared, processed and refined. Data engineering is the practice of taking raw data from a data source and process and refine it so that it is stored and organized for downstream use cases such as Data Analytics, Business Intelligence (BI), Reporting or machine learning (ML) model training.
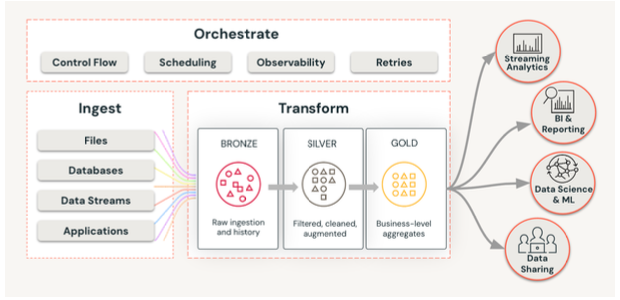
A generalised framework for Data Engineering can broadly be classified into:
- Ingestion Data ingestion is the process of bringing data from one or more data sources, with varying frequencies, types, formats and sizes into a data platform. These data sources can be files stored on-premises or on cloud storage services, databases, applications and streams of data which are real time or near real time. It is also advised to have a degree of governance during ingestion on the data stored for security and audit purposes and understand its lineage.
- Transformation Data transformation takes raw ingested data and uses a series of steps (referred to as “transformations”) to filter, standardize, clean, apply business rules and finally aggregate it to make the data usable for downstream systems. ETL (Extract Transform and Load) or ELT (Extract Load and Transform) mechanisms are used to accomplish such transformation and a popular architectural pattern used is the MEDALLION ARCHITECTURE, which defines three stages in the process — Bronze, Silver and Gold.
- Orchestration Data orchestration refers to the mechanism of creating, scheduling and monitoring a data pipeline which co-ordinates and orchestrates the different stages of ingestion and transformation for better control, manage status of the runs, handle failures and automation in general.
Challenges of data engineering in the AI era
Data engineers are the workhorses who build and maintain the ETL pipelines and the data infrastructure that underpins analytics and AI workloads. In this fast paced landscape and ever changing dynamics the data engineers face specific challenges like:
Handle Real-time Streaming data: From IOT sensors to mobile applications to mission critical systems, more and more data is created and streamed in real time and requires low-latency processing so it can be used in real-time analytics and decision-making.
Reliable data pipelines and Scalability: With data coming in large quantities and often in real time, scaling the compute infrastructure that runs data pipelines is challenging, especially when trying to keep costs low and performance high. Running data pipelines reliably, monitoring data pipelines and troubleshooting when failures occur and solve issues in a timely manner to maintain business as usual are some of the most important responsibilities of data engineers.
Data quality: “What you sow is what you reap” ,hence, “Garbage in then its garbage out.” High data quality is essential to training high-quality models and gaining actionable insights from data. Ensuring data quality is a key challenge for data engineers.
Data Governance, Compliance and Security: Data governance is becoming a key challenge for organizations who find their data spread across multiple systems with increasingly larger numbers of internal teams looking to access and utilize it for different purposes. Securing and governing data is also an important regulatory concern many organizations face, especially in highly regulated industries. Data leaks, regulatory compliances like HIPAA, GDPR, CCPA etc will jeopardise the entire business and credibility of the organization.
These challenges call for the importance of choosing the right data strategy, architecture and platform for the business in the age of AI. Arriving at the right platform can improve the overall experience and productivity of data practitioners, including data engineers, by using AI to assist with daily engineering tasks.
Lakehouse Architecture
